
When building a hosting company, there's an obvious shortcut. Buy a license for an existing panel, plug it into the servers, and start selling. Plenty of providers do it. WHMCS, Blesta, or some white-label solution that gives you a control panel, billing, and basic server management out of the box. Up and running in a week.
CubePath looked at that path and decided against it. Instead, a huge chunk of resources went into building a custom API and control panel from the ground up. It was slower, more expensive, and far more complex than buying something off the shelf. It's also the single best decision the company has made.
This post explains why that call was made, how the platform is architected, and why it's the reason CubePath can ship new products faster than providers ten times its size.
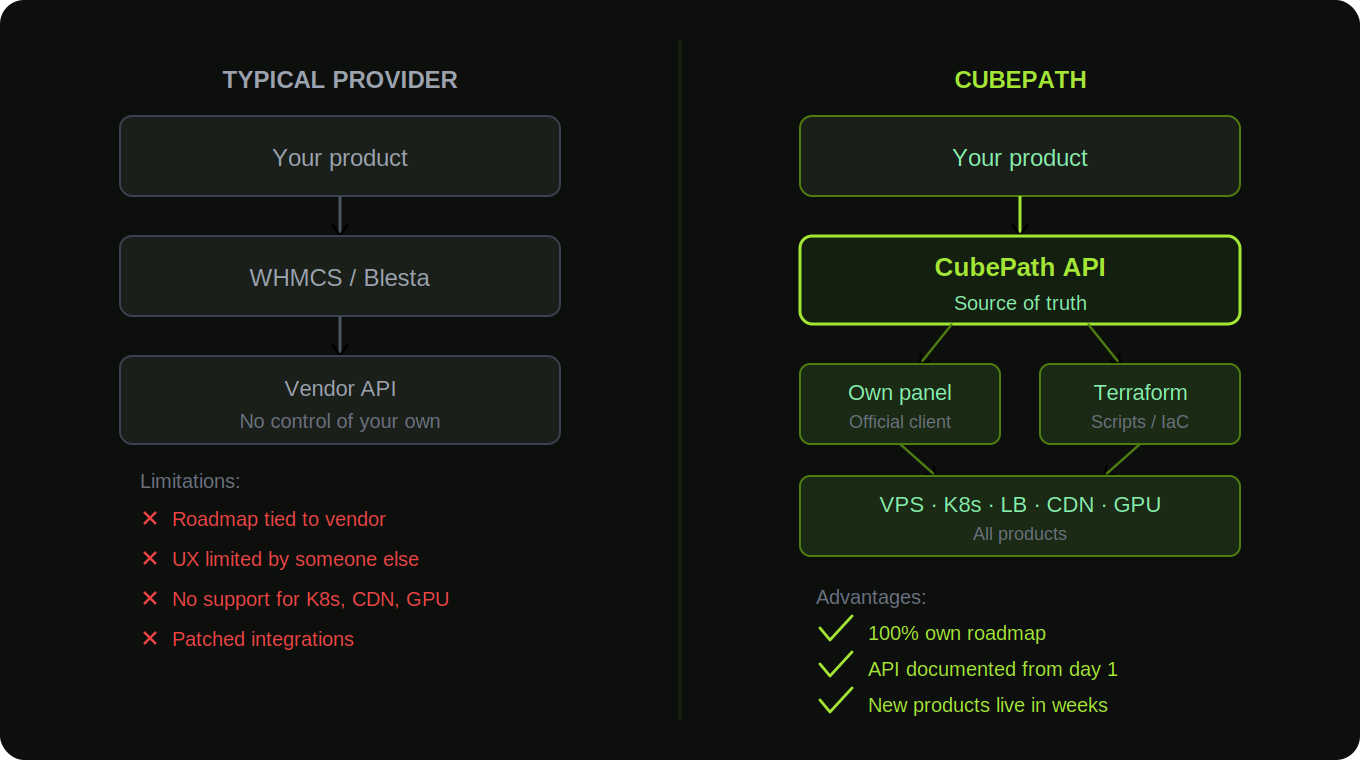
Why Not Use What Already Exists
The problem with third-party panels isn't that they're bad. They work fine for basic hosting. The problem is what happens when you want to do something they didn't plan for.
CubePath wanted to launch Managed Kubernetes. No off-the-shelf panel supports that. It wanted to offer Anycast Load Balancers. Not in the panel. CDN with custom caching rules? GPU clusters? Multi-region private networking with MTU 9000? None of it exists in any third-party hosting panel.
So a provider ends up in one of two places. Either it limits its product to what the panel supports, which means looking exactly like every other provider using the same panel. Or it starts hacking features on top of it, building custom integrations around someone else's architecture, patching around their limitations, and fighting their update cycle every time they push a new version that breaks the customizations.
The product roadmap becomes tied to someone else's roadmap. The user experience is constrained by someone else's UI decisions. And the ability to innovate is limited by what can be bolted onto a system that was never designed for what's being built.
CubePath didn't want any of that. The goal was full control over every product, every feature, and every pixel of the experience delivered to customers.
API-First: Everything Starts with the API
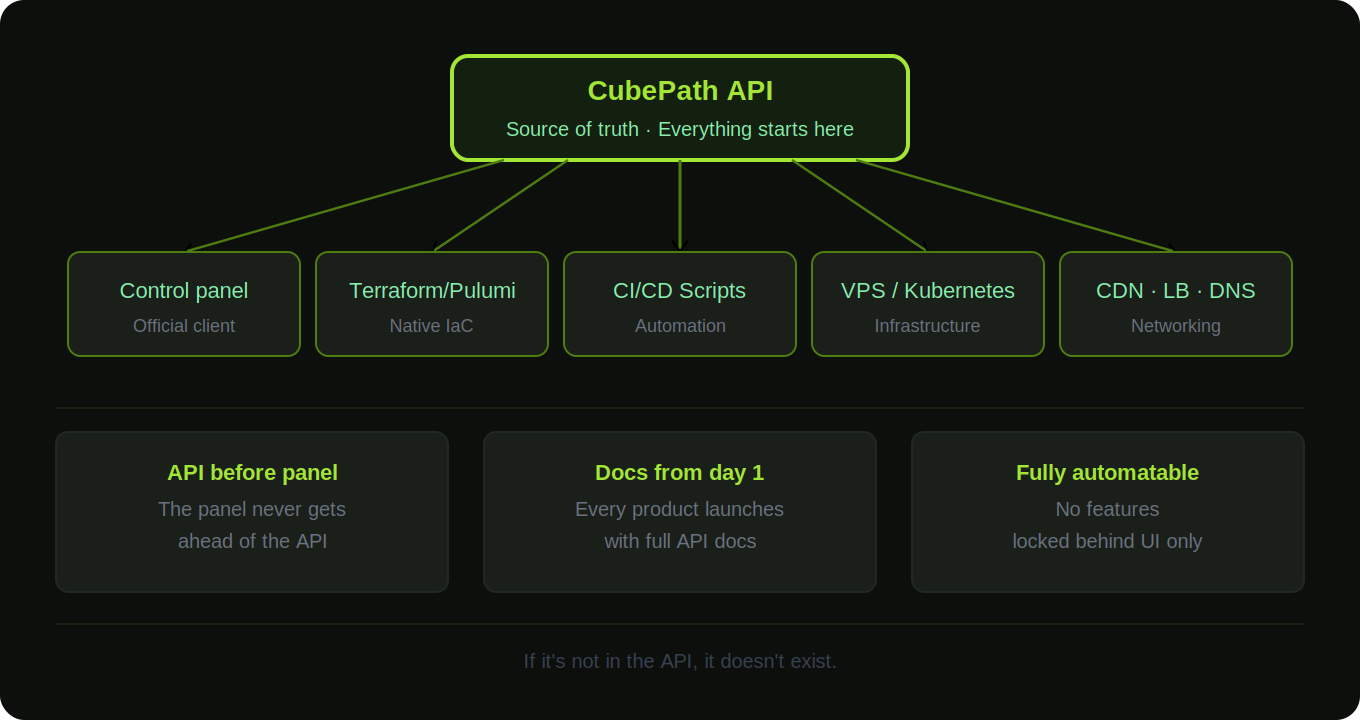
The foundation of the entire CubePath platform is the API. Not the panel. The API.
Every product at CubePath exists as an API first. When a new feature gets built, the first thing that's developed is the API endpoint. The control panel is just a client that consumes that API, the same way a customer's Terraform script or custom automation would.
This sounds like a technical detail, but it changes everything about how the platform works:
If it's not in the API, it doesn't exist. This forces clean architecture. Every action, from deploying a VPS to creating a Kubernetes cluster to configuring a Load Balancer, has a well-defined API call behind it. There's no hidden functionality that only works through the UI. Everything a customer can do in the panel can be automated through the API.
The panel can never be ahead of the API. Because the panel is built on top of the API, not alongside it, they're always in sync. There's no "a button was added in the panel but the API doesn't support it yet" situation. The API is the source of truth.
Customers get automation from day one. When a new product launches, it has API documentation on launch day. Not weeks later, not "coming soon." The API was literally the first thing built for that product. Customers who want to integrate CubePath into their CI/CD pipelines, Terraform workflows, or custom orchestration can do it immediately.
Third-party integrations become straightforward. Because the API is clean and consistent across all products, building integrations with tools like Terraform, Ansible, Pulumi, or custom scripts is predictable. Learn the pattern once and it applies to every product CubePath offers.
Microservices: Each Product Is Its Own Service
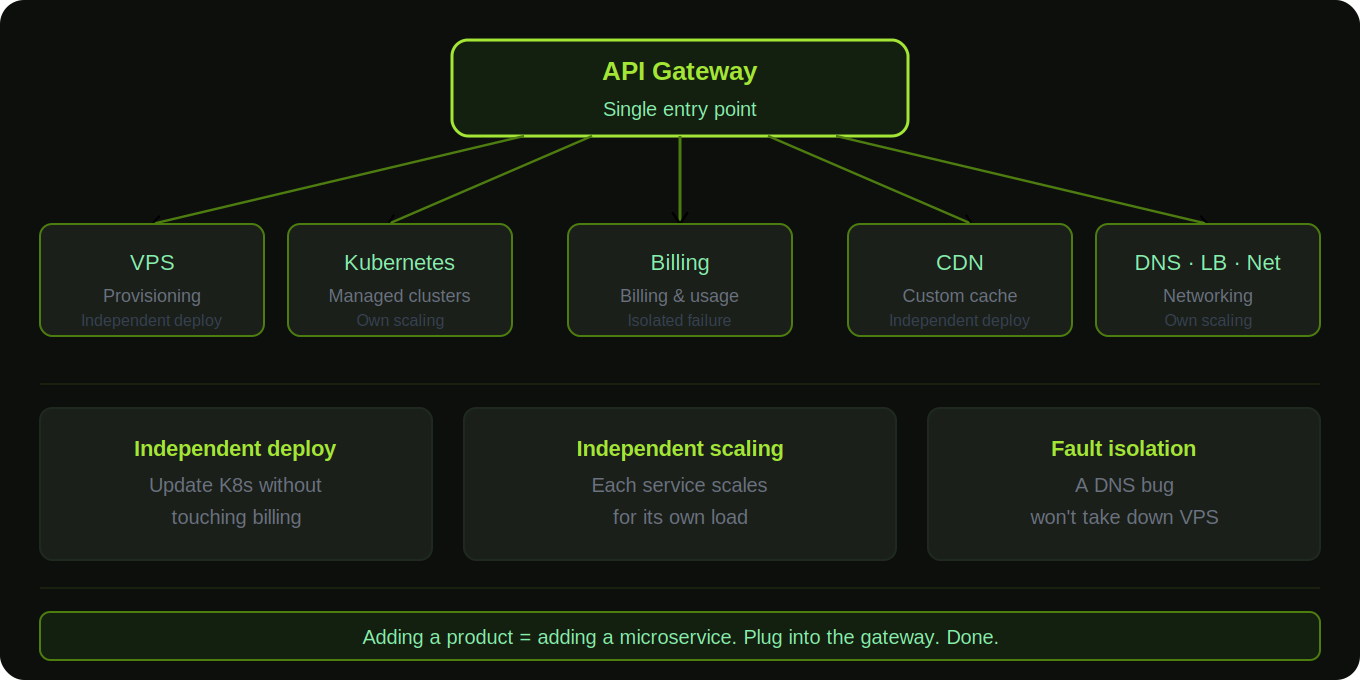
The CubePath platform isn't a monolith. Each product runs as an independent microservice: VPS provisioning, Managed Kubernetes, DNS, Load Balancers, CDN, billing, networking. Each one is its own service with its own codebase, its own deployment pipeline, and its own scaling.
Why does this matter?
Independent deployment. When an update ships for the Kubernetes service, the VPS provisioning service doesn't know and doesn't care. There's no risk of a DNS update breaking the billing system. Each service is deployed, updated, and rolled back independently. This is what allows daily updates without sweating.
Independent scaling. During a traffic spike in VPS provisioning, that service scales without touching anything else. The Kubernetes control plane management service has completely different scaling characteristics than the CDN configuration service. Microservices let each one scale for its own workload.
Parallel development. The engineering team can work on multiple products simultaneously without stepping on each other. The team working on GPU cluster support isn't blocked by the team improving the Load Balancer service. Different repos, different pipelines, different deployment cycles.
Fault isolation. If one service has a problem, the blast radius is contained. A bug in the DNS management service doesn't take down VPS provisioning. The panel keeps working, the API keeps responding, and the affected service gets fixed without cascading failures across the platform.
Adding new products is adding a new service. When the decision was made to build Managed Kubernetes, there was no need to modify a monolith or find a place to wedge it into an existing codebase. A new service was built, connected to the API gateway, and it was live. Same with CDN. Same with GPU clusters when they launch. The architecture is designed for this.
CubePath Runs on What It Sells
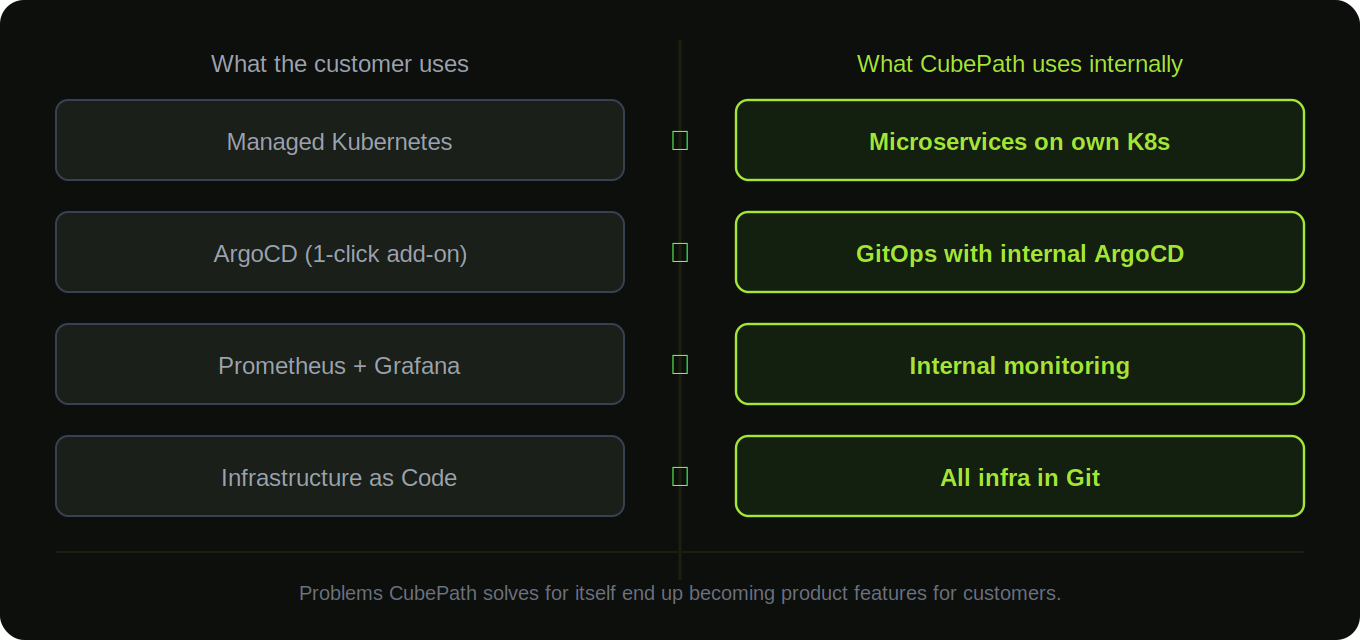
Here's something that defines CubePath's philosophy: the platform runs on Kubernetes. The same Kubernetes sold as a managed product to customers.
The microservices are deployed as containers in Kubernetes clusters. The infrastructure is defined as code. Deployments go through CI/CD pipelines. The same tools and practices recommended to customers are used internally because the team believes in them enough to bet the entire platform on them.
Infrastructure as Code everywhere. Every piece of platform infrastructure is defined in code and version controlled. Server configurations, network policies, Kubernetes manifests, monitoring rules. All of it lives in Git. Need to recreate a service from scratch? Done. Need to roll back a change? It's a git revert. There's no "that one server someone configured manually three years ago and nobody knows how it works."
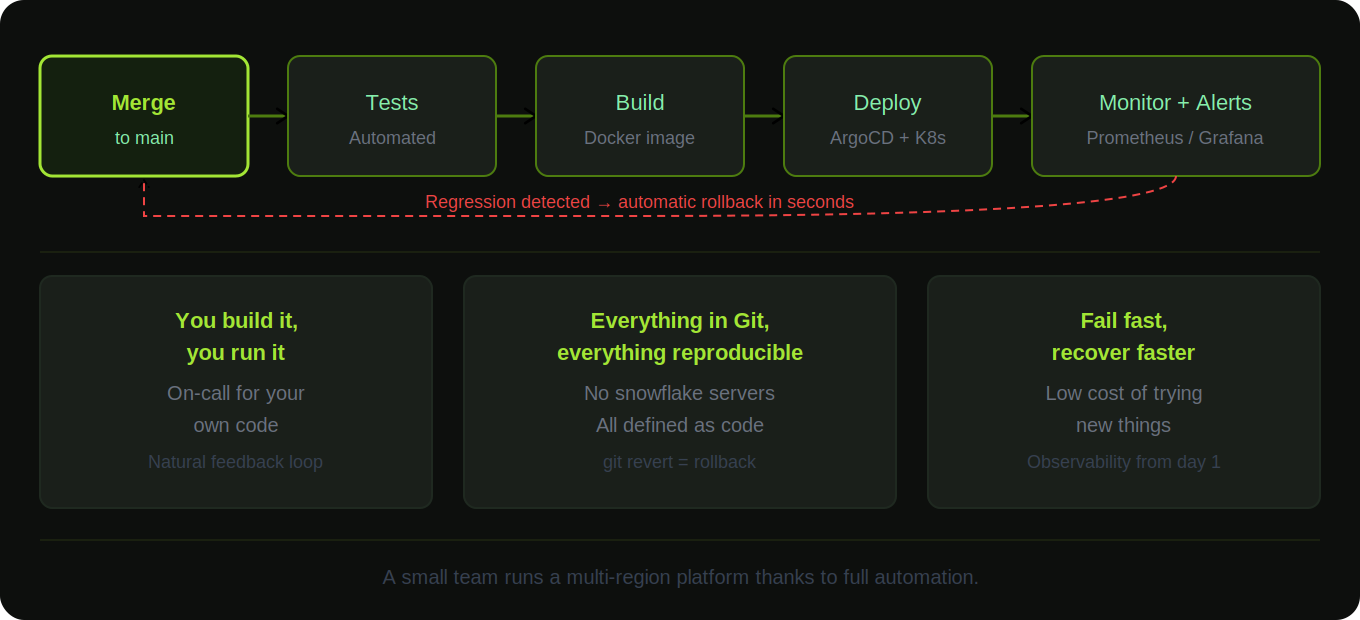
CI/CD on everything. A merge to main triggers the pipeline. Tests run, images build, deployments roll out. Nobody SSHs into servers to deploy code. There are no "deployment days" where everyone holds their breath. Shipping code happens continuously, multiple times a day, because the pipeline handles it.
GitOps with ArgoCD. The same ArgoCD offered as a one-click add-on in Managed Kubernetes is what manages the platform's own deployments. Git is the source of truth for cluster state. ArgoCD watches the repos and keeps everything in sync. If someone makes a manual change in a cluster, ArgoCD reverts it. Need to roll back? Revert the commit and ArgoCD takes care of the rest.
Monitoring and observability from day one. Every service ships with metrics, structured logging, and tracing. The team knows how every API call performs, where time is spent, and when something is degrading before it becomes a customer-visible issue. Prometheus, Grafana, alerting rules. The same stack offered as an add-on is the stack used internally.
This isn't just philosophical alignment. It makes CubePath better at running Kubernetes for customers because the team runs it for the platform every day. The problems solved internally are the same problems customers face, and the solutions built often end up as product features.
The DevOps Philosophy That Ties It All Together
The tooling matters, but the culture behind it matters more. CubePath operates with a DevOps mindset that's core to how the company works:
The people who build it, run it. Engineers don't write code and throw it over a wall to an ops team. The same people who develop a service are responsible for deploying it, monitoring it, and being on call for it. This creates a natural feedback loop: if your code causes alerts at 2 AM, you write better code.
Small team, big output. Thanks to the investment in automation, CI/CD, and Infrastructure as Code, a small engineering team can manage a platform that serves thousands of customers across multiple regions. Headcount isn't burned on manual deployments, manual server configuration, or manual incident response. The systems handle the routine work, and the humans focus on building new things.
Everything is reproducible. No snowflake servers, no manual configurations, no "it works on my machine." Every environment, from development to staging to production, is defined in code and can be recreated at will. This gives confidence to experiment, because getting back to a known good state is always possible.
Fail fast, recover faster. With proper CI/CD, rollbacks, and observability, the cost of trying something new is low. If a deployment introduces a regression, monitoring catches it, rollback happens in seconds, and the fix goes in. This speed comes from the investment in tooling and architecture, not from taking shortcuts on quality.
The Result: CubePath Ships Products Faster
All of this architecture, the API-first approach, the microservices, the Kubernetes platform, the DevOps culture, it compounds. Each new product is faster than the last because the foundation is already there.
When Managed Kubernetes was built, the starting point wasn't zero. The API gateway was there. The authentication system was there. The billing integration was there. The monitoring stack was there. The CI/CD pipeline was there. The Kubernetes-specific logic was built as a new microservice, plugged into the existing platform, and it was live.
When CDN was built, same thing. New service, same platform. API ready on launch day, panel integration ready on launch day, monitoring ready on launch day.
This is the compounding advantage of building a custom platform. Every product shipped makes the next one easier. And because the API is the foundation, every product is automatable from day one. No customer has to wait for "API support to be added later." It's already there, because the API is how everything gets built.
Compare that to a provider running a third-party panel. Every new product is a custom integration, a hack on top of someone else's system, a feature request that may or may not get implemented by the panel vendor. Their speed is limited by someone else's priorities.
CubePath's speed is limited only by how fast the team can write good code. And with the platform that's been built, that's pretty fast.
The Hardest Investment Is the One That Pays Off Most
Building a custom API and control panel has been the hardest thing done at CubePath. In the early days, every competitor was already selling services while the team was still writing API endpoints and designing database schemas. It would have been so much easier to buy a panel and start selling immediately.
But every month that passes, the gap between what CubePath can do and what a provider on a third-party panel can do gets wider. CubePath can launch a new product in weeks. They need to wait for their panel to support it, or spend months building a custom integration. CubePath can change the customer experience overnight. They're constrained by someone else's UI framework. CubePath can offer a consistent, fully documented API across every product. They have a patchwork of integrations that may or may not work together.
The upfront cost was real. But the long-term advantage is something that can't be bought off the shelf. It's the kind of advantage that only comes from building it from scratch, brick by brick, API endpoint by API endpoint.
And this is just getting started.