
There's a shortcut most hosting providers take. They rent capacity from a larger network, put some servers behind it, and call it their infrastructure. It works, until it doesn't. When the upstream has a routing issue, you have a routing issue. When their peering gets congested, your customers feel it. You have zero control over the path traffic takes to reach your servers.
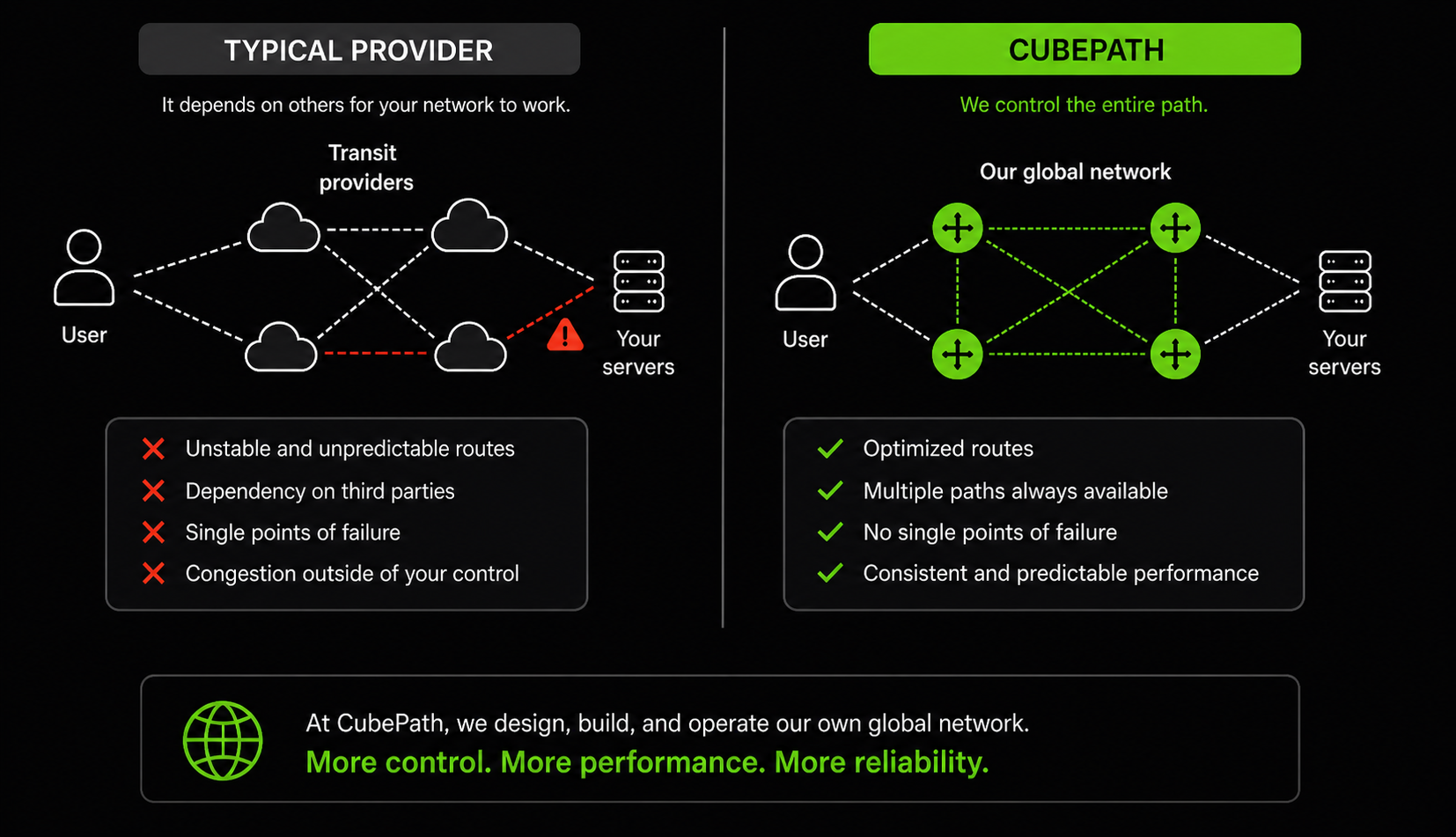
We decided early on that CubePath would own its network. Not resell someone else's. We built a global backbone with Points of Presence in Miami, Houston, Virginia, and Spain, running BGP multihoming with multiple transit providers and the ability to announce routes via Anycast from any of our PoPs.
This post explains why we made that investment and what it means for anything you run on CubePath.
Our Network: PoPs, Backbone, and Why Location Matters
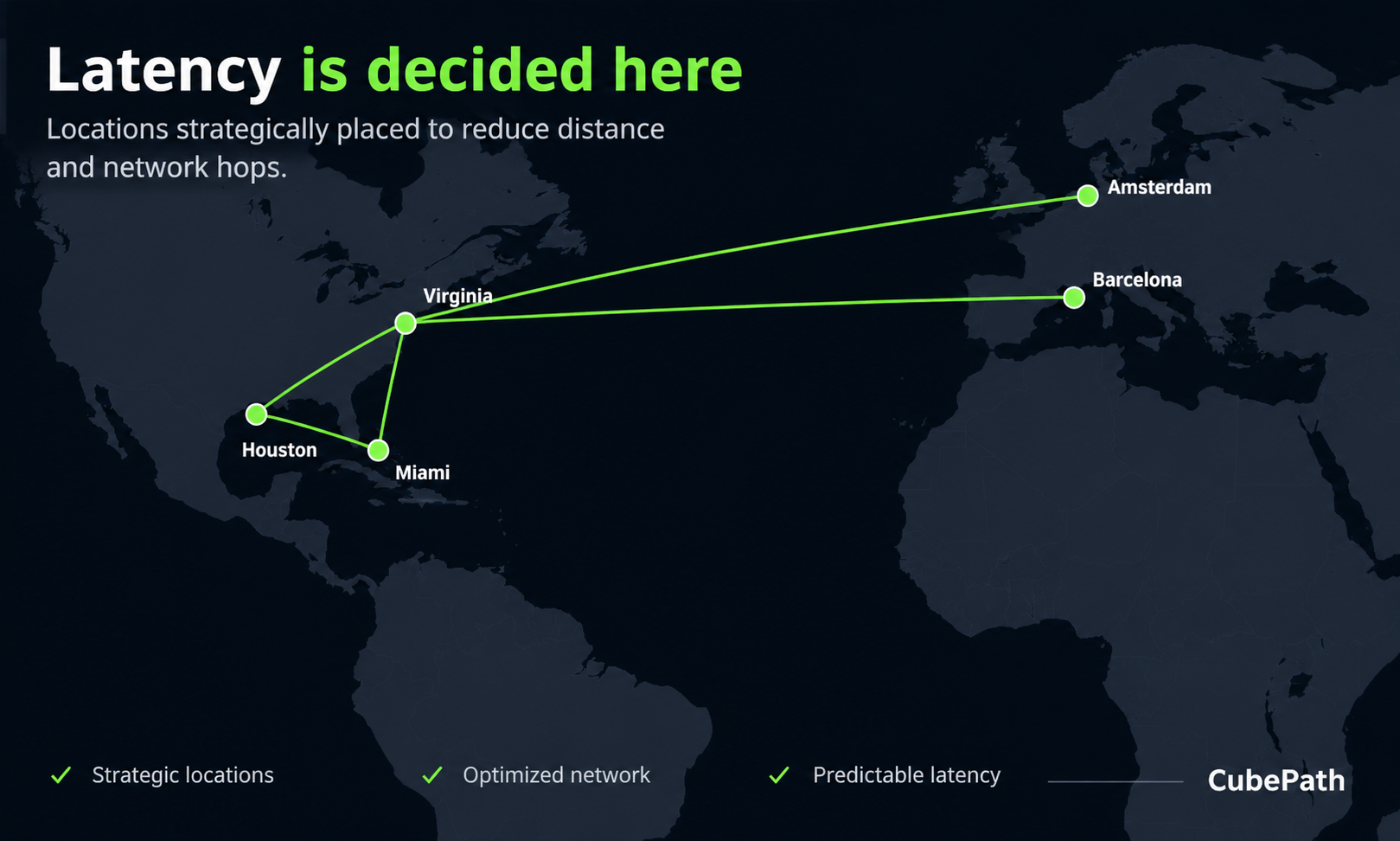
CubePath operates Points of Presence in strategic locations across the Americas and Europe:
- Miami for Latin America and the Caribbean
- Houston for the central United States and Mexico
- Virginia for the US East Coast and transatlantic traffic
- Spain for Southern Europe, the Mediterranean, and North Africa
Each PoP isn't just a server in a datacenter. It's a full network presence with its own routers, transit connections, and peering. All PoPs are interconnected through our private backbone, so traffic between locations stays on our network instead of bouncing through the public internet.
Why does the physical location of PoPs matter? Because physics. Light in fiber travels fast, but the distance still adds up. A user in Buenos Aires connecting to a server in Virginia has to cross 8,000+ km of fiber. That same user connecting through our Miami PoP cuts that distance dramatically. Multiply that by every request, every API call, every page load, and the difference in user experience is significant.
But having PoPs in the right places is only half the equation. The other half is how traffic gets routed to them.
BGP Multihoming: Multiple Paths, Zero Single Points of Failure
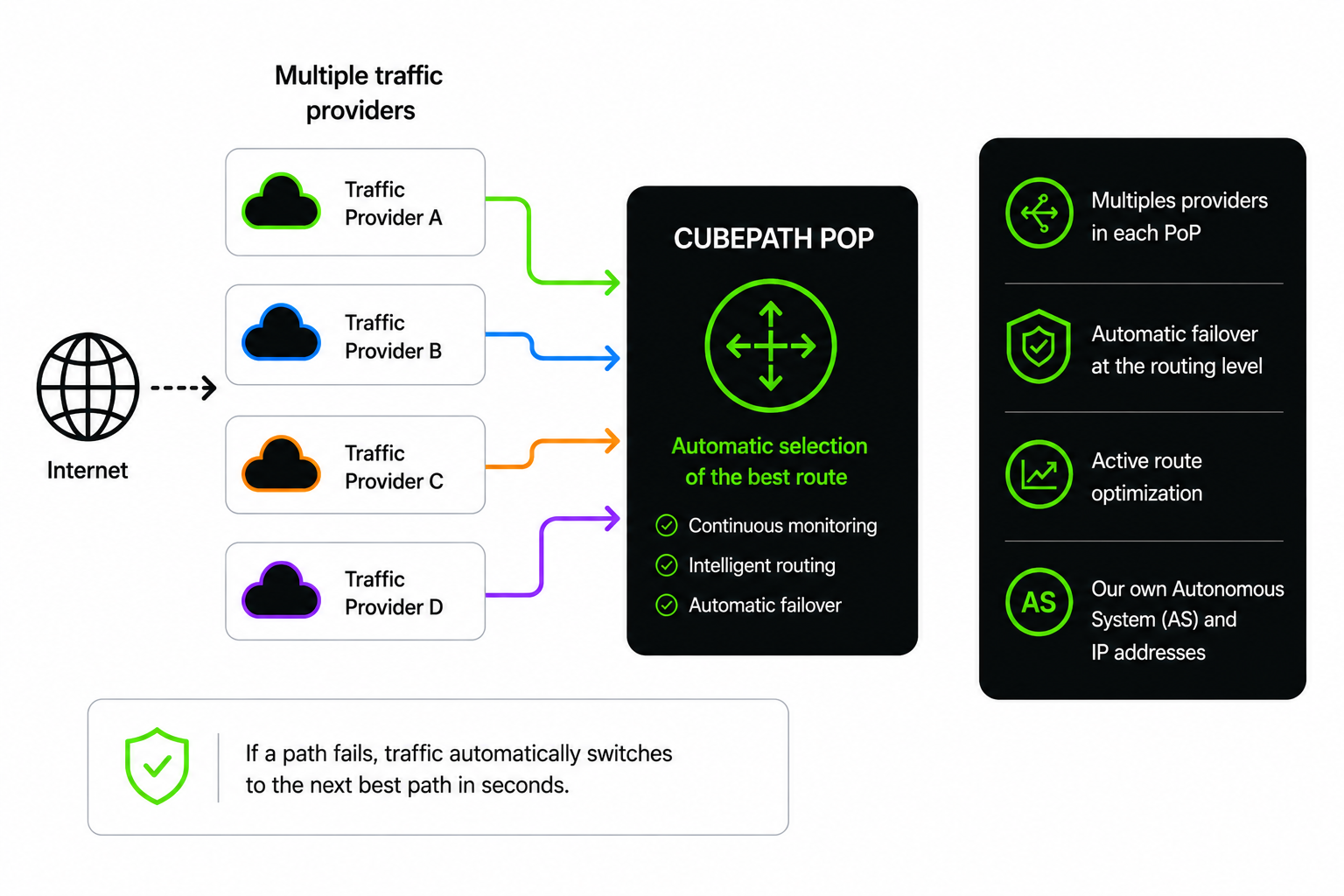
BGP (Border Gateway Protocol) is how the internet decides which path traffic takes to get from point A to point B. Every network on the internet announces its routes via BGP, and routers across the world use those announcements to figure out the best path.
Most small and mid-size providers have a simple BGP setup: one or two upstream transit providers. Traffic comes in through whatever path those upstreams offer, and that's it. If the upstream has a problem, your traffic has a problem.
CubePath runs BGP multihoming across all our PoPs. That means:
Multiple transit providers at every location. We don't depend on a single upstream anywhere. Each PoP has connections to several transit providers, so there's always more than one path for traffic to reach us. If one provider has a routing leak, a congestion issue, or goes down entirely, traffic automatically shifts to the next best path.
Active route optimization. BGP multihoming isn't just about redundancy. With multiple upstreams, we can influence which paths traffic takes. We optimize our BGP announcements so that traffic from different regions enters through the provider and path that offers the lowest latency. A user in São Paulo reaches us through a different path than a user in London, and both get the best route available.
Our own Autonomous System. CubePath operates its own AS number and IP space. This is what makes true multihoming possible. We're not borrowing someone else's address space or depending on their routing decisions. We announce our own prefixes to our own upstreams and control how the world sees our network.
Automatic failover at the routing level. When a transit provider has issues, BGP convergence happens automatically. Traffic re-routes through alternative paths without any manual intervention and without your services going down. This isn't application-level failover that takes minutes. It's network-level re-routing that happens in seconds.
Why Most Providers Don't Do This
BGP multihoming requires significant investment. You need your own AS number, your own IP allocations from a Regional Internet Registry, contracts with multiple transit providers at every location, and network engineers who understand BGP policy and route optimization. Most providers skip this because a single upstream is simpler and cheaper. The tradeoff is that their customers are at the mercy of that single provider's network quality and reliability.
We think that tradeoff is unacceptable for production infrastructure. If you're running services that matter, the network carrying your traffic should be resilient by design, not by luck.
Peering at Internet Exchanges: Fewer Hops, Faster Traffic
Beyond transit providers, CubePath peers directly at Internet Exchange Points (IXPs) in every region where we operate. An IX is a physical location where hundreds of networks connect to exchange traffic directly with each other, skipping the middlemen.
When two networks are both present at the same IX, they can peer directly. That means traffic between them doesn't have to go through a transit provider, which removes hops from the path and reduces latency. Instead of your traffic going from CubePath to a transit provider to another transit provider to the destination network, it goes from CubePath straight to the destination. One hop instead of three or four.
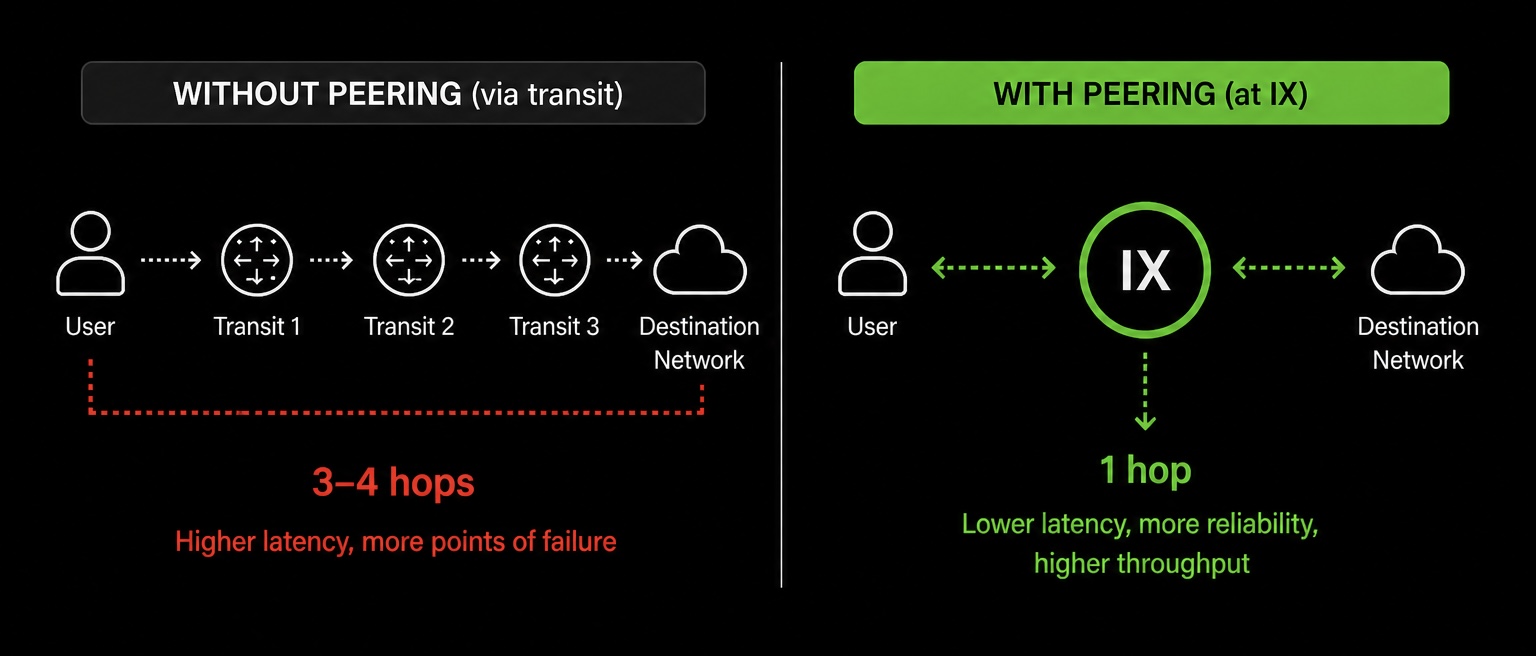
We peer at every IX we can because the goal is simple: keep our network as interconnected as possible and reduce the number of hops between CubePath and the rest of the internet.
Why this matters for latency. Every hop in a network path adds latency. A router needs to receive the packet, look up the route, and forward it. That takes time, usually a fraction of a millisecond, but it adds up across multiple hops. By peering directly with major networks, CDNs, cloud providers, and eyeball ISPs at IX locations, we cut those intermediate hops out of the equation. The result is measurably lower latency for your users.
Why this matters for reliability. Fewer hops means fewer things that can go wrong. Every router in the path is a potential point of failure or congestion. Direct peering at an IX removes those intermediate points entirely. If we're peered with a user's ISP at the same exchange, the traffic stays local to that facility. No long-haul transit, no third-party routing decisions, no surprises.
Why this matters for throughput. IX peering typically offers higher capacity and lower cost than transit. When a significant portion of your traffic goes to networks you peer with directly, you're not competing for bandwidth on a transit provider's congested links. The traffic flows over dedicated peering connections with capacity we control and monitor.
The more networks we peer with, the more traffic takes direct paths. And the more direct paths traffic takes, the faster and more reliable your services are for end users.
Anycast: One IP, Served from the Nearest PoP
Anycast is a routing technique where the same IP address is announced from multiple locations simultaneously. When a user sends a request to an Anycast IP, BGP routing naturally directs them to the nearest PoP announcing that address. The user doesn't choose. The network does it automatically based on routing proximity.
CubePath uses Anycast across our PoP network. Here's what that enables:
Geographic traffic steering without DNS tricks. Traditional approaches to directing users to the nearest server rely on GeoDNS, which resolves the same hostname to different IPs based on the user's location. It works, but it's slow to update, imprecise, and depends on DNS TTLs being respected. Anycast skips all of that. One IP, announced from every PoP, and the network handles the rest.
Instant failover between locations. If a PoP goes offline, BGP withdraws the Anycast route from that location. Traffic automatically redirects to the next nearest PoP within seconds. No DNS propagation delays, no TTL waiting, no manual intervention. The IP stays the same, the user gets rerouted transparently.
Reduced latency on first connection. TLS handshakes are latency-sensitive. They require multiple round trips between client and server before any data flows. When the Anycast IP resolves to the nearest PoP, those round trips are shorter, and the connection establishes faster. For HTTPS services, this translates directly to faster time-to-first-byte.
Natural DDoS resilience. Anycast distributes incoming traffic across all PoPs announcing the address. During a volumetric DDoS attack, the traffic gets spread across multiple locations instead of hitting a single point. Each PoP absorbs a fraction of the attack, making it much harder to overwhelm any single location.
How We Use Anycast at CubePath
A good example is our DNS infrastructure. CubePath's DNS resolvers are announced via Anycast from all our PoPs. When your server makes a DNS query, it reaches the nearest resolver automatically. A server in Spain queries the local PoP. A server in Miami queries that one. Same IP, different physical location, lowest possible latency. If a PoP goes down, DNS queries seamlessly route to the next closest one without any configuration change.
We also use Anycast as the foundation for our CDN and DDoS mitigation services. Traffic from end users hits the nearest PoP first, where it can be filtered, cached, or forwarded to the origin server over our private backbone. This architecture means that both the security layer and the content delivery layer benefit from geographic distribution without customers needing to configure anything.
How This All Connects
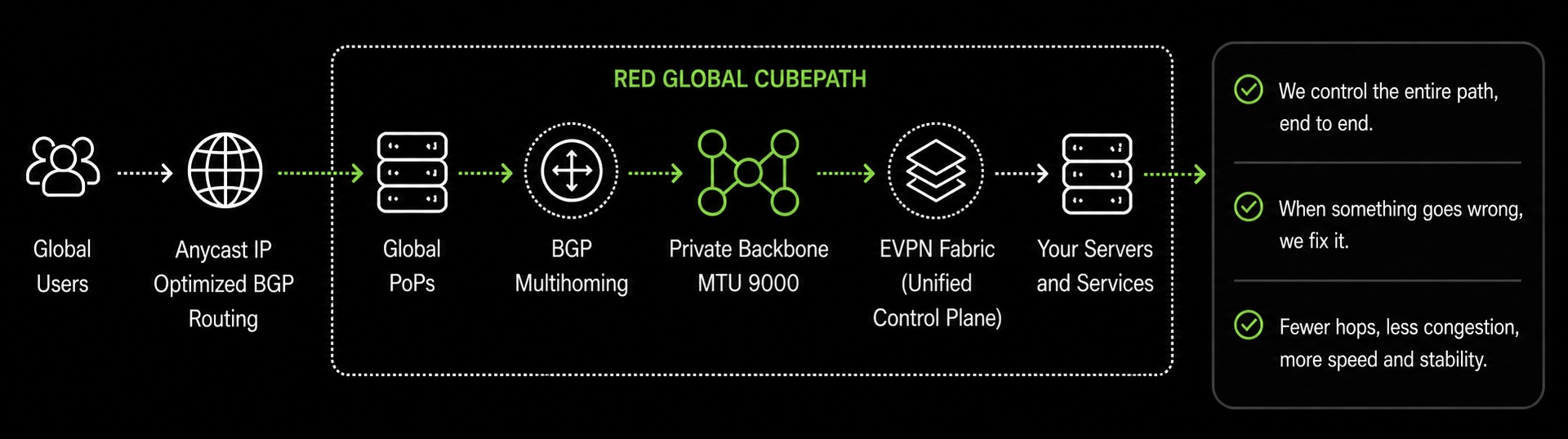
Our global network isn't a collection of isolated features. The PoPs, BGP multihoming, Anycast, and the private backbone with MTU 9000 all work together as a single infrastructure.
Traffic enters through the nearest PoP thanks to Anycast and optimized BGP routes. It travels across our private backbone to reach the servers running your workloads, with MTU 9000 ensuring that internal data transfer is as efficient as possible. If any component fails, whether it's a transit provider, a PoP, or a server, the network re-routes automatically at the BGP level.
Internally, our network fabric runs on EVPN (Ethernet VPN), the same technology hyperscale cloud providers use. EVPN uses BGP to learn where every server and address lives on the network, so traffic is forwarded intelligently instead of being flooded everywhere like in traditional setups. It's what allows us to extend private networks seamlessly between PoPs, handle multi-site connectivity natively, and scale the fabric as we add more servers and locations without the network degrading. The same BGP that handles our internet routing, peering, and Anycast also drives our internal fabric. One unified control plane for the entire network.
This is what makes CubePath different from providers that rent network capacity from someone else. We control the entire path, from the user's first packet to the server processing the request. When something goes wrong, we don't open a ticket with an upstream. We fix it ourselves.
For teams running latency-sensitive APIs, globally distributed applications, real-time services, or anything where network performance directly impacts user experience, this is the kind of network you want underneath your infrastructure.
Where We're Going
We're continuing to expand our PoP footprint and add peering connections at every location. More PoPs means shorter paths to more users. More peering means less dependence on transit and better routing to major networks and eyeball ISPs.
As we grow CubePath Managed Kubernetes, GPU clusters, and the rest of our platform, the network remains the foundation. Fast, redundant, globally distributed, and fully under our control.
We built this network because we believe infrastructure providers should own their network, not rent it. Everything we offer on CubePath sits on top of this foundation, and we think you can feel the difference.