
Hay un atajo que toman la mayoría de proveedores de hosting. Alquilan capacidad de una red más grande, ponen servidores detrás y lo llaman su infraestructura. Funciona, hasta que deja de funcionar. Cuando el upstream tiene un problema de enrutamiento, tú tienes un problema de enrutamiento. Cuando su peering se congestiona, tus clientes lo notan. Tienes cero control sobre el camino que toma el tráfico para llegar a tus servidores.
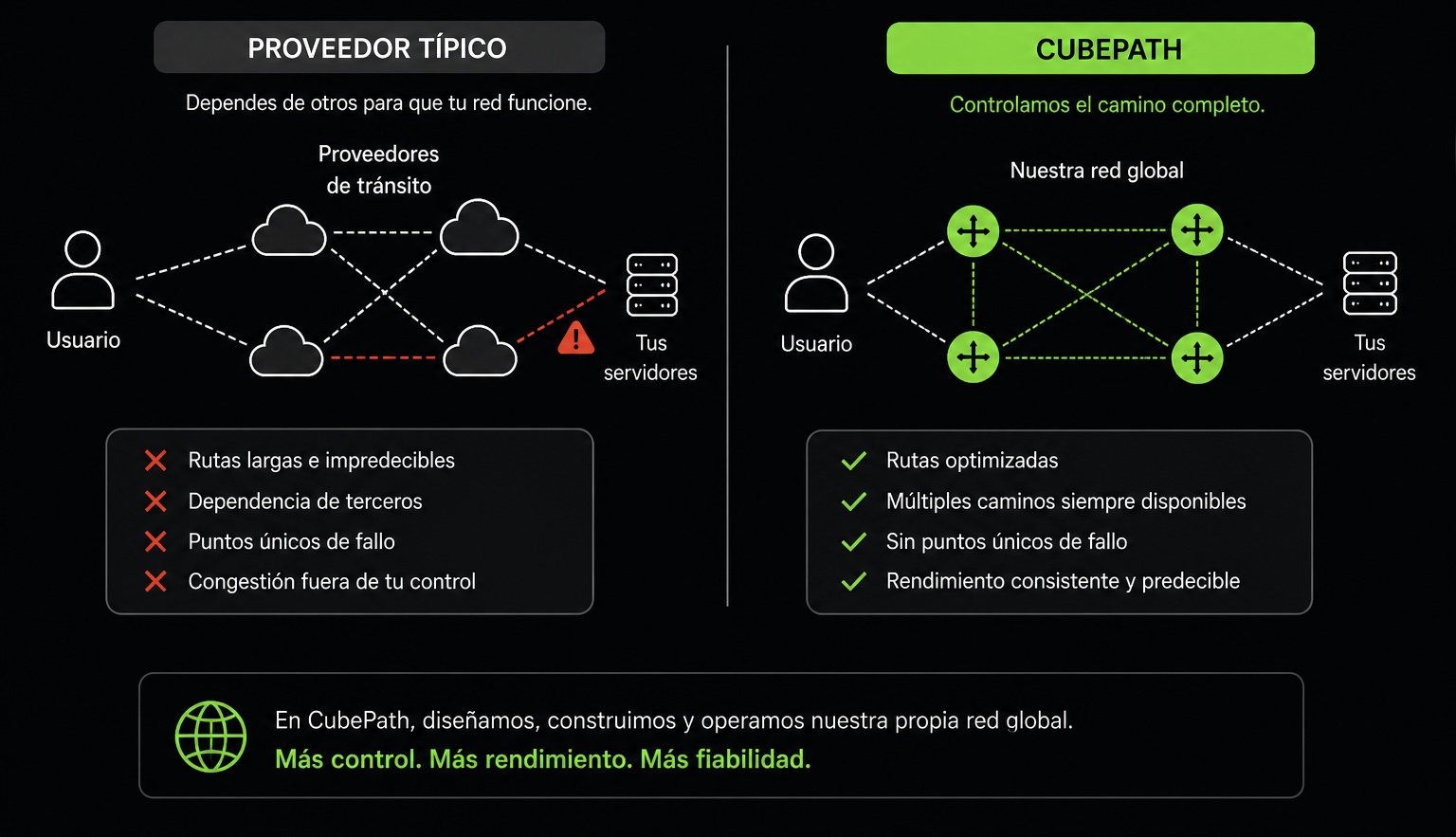
Decidimos desde el principio que CubePath sería dueño de su red. No revendería la de otro. Hemos construido un backbone global con Puntos de Presencia en Miami, Houston, Virginia y España, ejecutando BGP multihoming con múltiples proveedores de tránsito y la capacidad de anunciar rutas vía Anycast desde cualquiera de nuestros PoPs.
Este post explica por qué hicimos esa inversión y qué significa para cualquier cosa que ejecutes en CubePath.
Nuestra Red: PoPs, Backbone, y Por Qué la Ubicación Importa
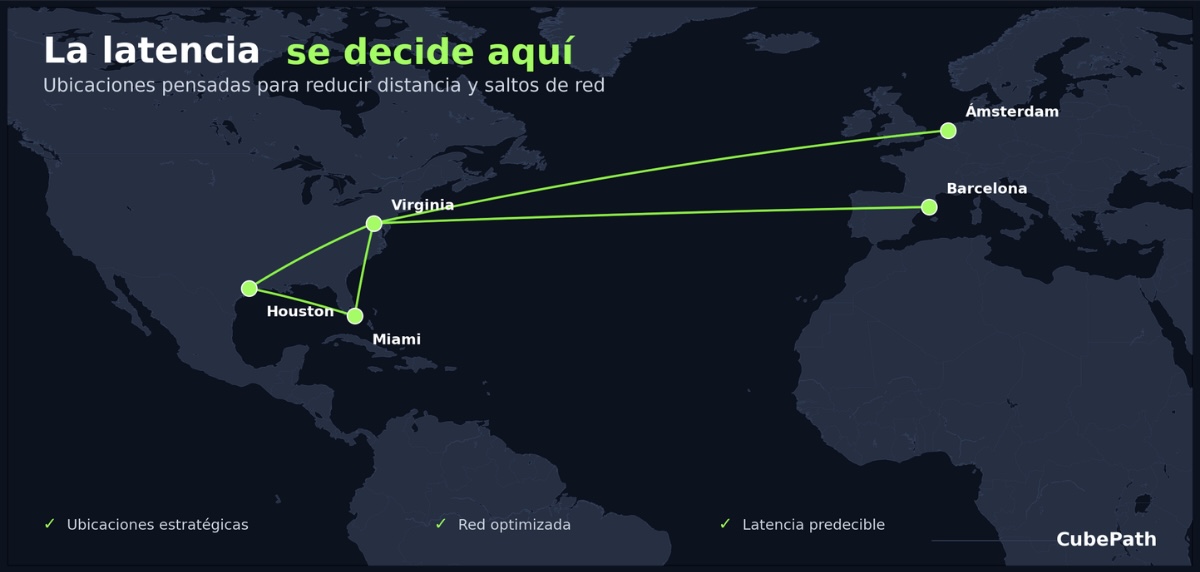
CubePath opera Puntos de Presencia en ubicaciones estratégicas entre América y Europa:
- Miami para Latinoamérica y el Caribe
- Houston para el centro de Estados Unidos y México
- Virginia para la Costa Este de EE.UU. y el tráfico transatlántico
- España para el sur de Europa, el Mediterráneo y el norte de África
Cada PoP no es simplemente un servidor en un datacenter. Es una presencia de red completa con sus propios routers, conexiones de tránsito y peering. Todos los PoPs están interconectados a través de nuestro backbone privado, así que el tráfico entre ubicaciones se queda en nuestra red en vez de rebotar por internet público.
¿Por qué importa la ubicación física de los PoPs? Porque la física manda. La luz en la fibra viaja rápido, pero la distancia sigue sumando. Un usuario en Buenos Aires conectándose a un servidor en Virginia tiene que cruzar más de 8.000 km de fibra. Ese mismo usuario conectándose a través de nuestro PoP en Miami reduce esa distancia drásticamente. Multiplica eso por cada petición, cada llamada a API, cada carga de página, y la diferencia en experiencia de usuario es significativa.
Pero tener PoPs en los sitios correctos es solo la mitad de la ecuación. La otra mitad es cómo se enruta el tráfico hacia ellos.
BGP Multihoming: Múltiples Caminos, Cero Puntos Únicos de Fallo
BGP (Border Gateway Protocol) es cómo internet decide qué camino toma el tráfico para ir del punto A al punto B. Cada red en internet anuncia sus rutas vía BGP, y los routers de todo el mundo usan esos anuncios para calcular el mejor camino.
La mayoría de proveedores pequeños y medianos tienen un setup BGP simple: uno o dos proveedores de tránsito upstream. El tráfico entra por el camino que esos upstreams ofrezcan, y ya está. Si el upstream tiene un problema, tu tráfico tiene un problema.
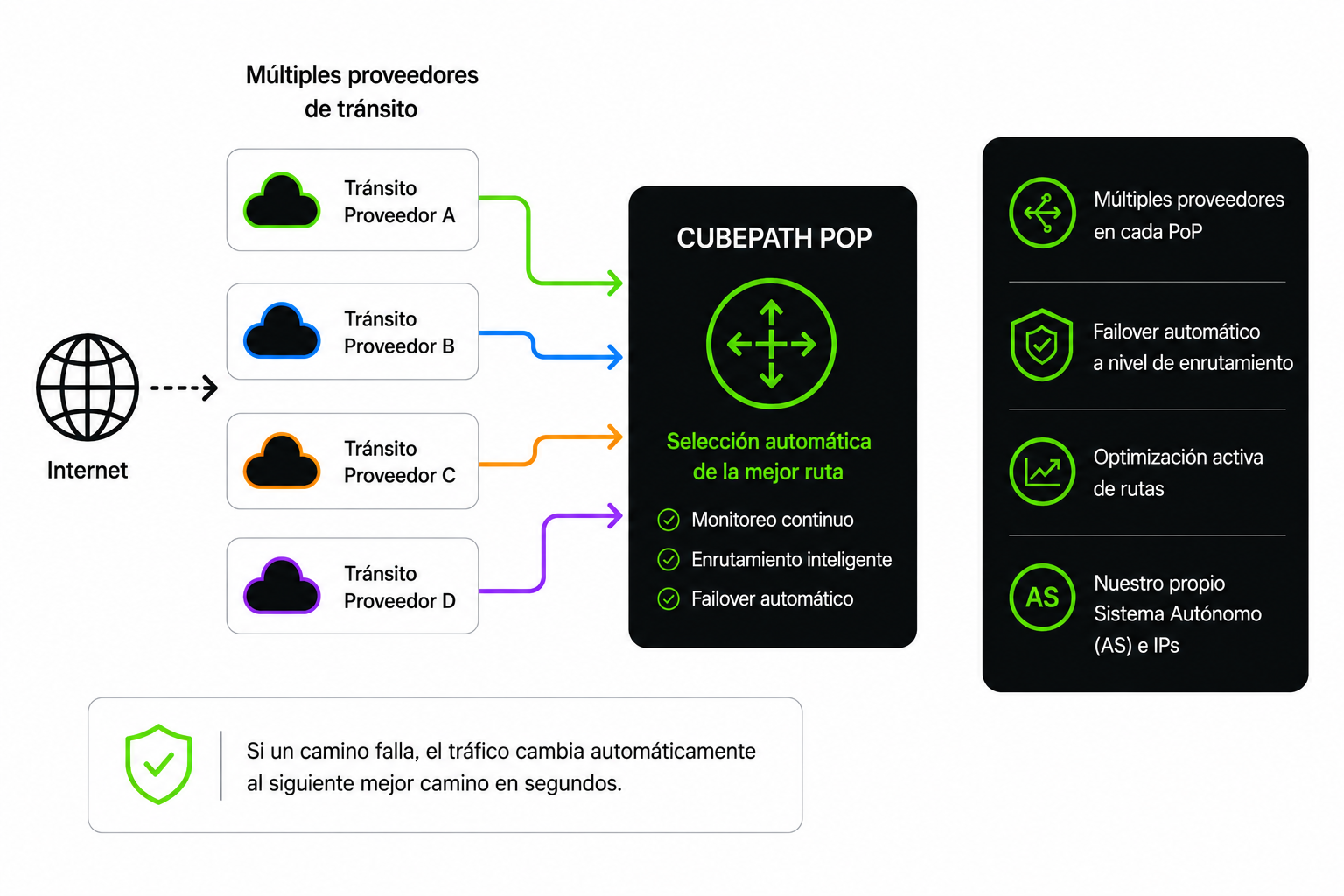
CubePath ejecuta BGP multihoming en todos nuestros PoPs. Eso significa:
Múltiples proveedores de tránsito en cada ubicación. No dependemos de un solo upstream en ningún sitio. Cada PoP tiene conexiones a varios proveedores de tránsito, así que siempre hay más de un camino para que el tráfico nos llegue. Si un proveedor tiene un route leak, un problema de congestión o se cae completamente, el tráfico cambia automáticamente al siguiente mejor camino.
Optimización activa de rutas. BGP multihoming no es solo redundancia. Con múltiples upstreams, podemos influir en qué caminos toma el tráfico. Optimizamos nuestros anuncios BGP para que el tráfico desde diferentes regiones entre por el proveedor y camino que ofrezca la menor latencia. Un usuario en São Paulo nos llega por un camino diferente que un usuario en Londres, y ambos obtienen la mejor ruta disponible.
Nuestro propio Sistema Autónomo. CubePath opera su propio número AS y su propio espacio IP. Esto es lo que hace posible el multihoming real. No estamos usando el espacio de direcciones de otro ni dependiendo de sus decisiones de enrutamiento. Anunciamos nuestros propios prefijos a nuestros propios upstreams y controlamos cómo el mundo ve nuestra red.
Failover automático a nivel de enrutamiento. Cuando un proveedor de tránsito tiene problemas, la convergencia BGP ocurre automáticamente. El tráfico se re-enruta por caminos alternativos sin intervención manual y sin que tus servicios se caigan. Esto no es failover a nivel de aplicación que tarda minutos. Es re-enrutamiento a nivel de red que ocurre en segundos.
Por Qué la Mayoría de Proveedores No Hacen Esto
BGP multihoming requiere una inversión significativa. Necesitas tu propio número AS, tus propias asignaciones IP de un Registro Regional de Internet, contratos con múltiples proveedores de tránsito en cada ubicación, e ingenieros de red que entiendan políticas BGP y optimización de rutas. La mayoría de proveedores se saltan esto porque un solo upstream es más simple y más barato. La contrapartida es que sus clientes están a merced de la calidad y fiabilidad de la red de ese único proveedor.
Creemos que esa contrapartida es inaceptable para infraestructura de producción. Si estás ejecutando servicios que importan, la red que transporta tu tráfico debería ser resiliente por diseño, no por suerte.
Peering en Internet Exchanges: Menos Saltos, Tráfico Más Rápido
Más allá de los proveedores de tránsito, CubePath hace peering directo en Internet Exchange Points (IXPs) en cada región donde operamos. Un IX es una ubicación física donde cientos de redes se conectan para intercambiar tráfico directamente entre ellas, saltándose a los intermediarios.
Cuando dos redes están presentes en el mismo IX, pueden hacer peering directo. Eso significa que el tráfico entre ellas no tiene que pasar por un proveedor de tránsito, lo que elimina saltos del camino y reduce la latencia. En vez de que tu tráfico vaya de CubePath a un proveedor de tránsito, a otro proveedor de tránsito, a la red de destino, va de CubePath directamente al destino. Un salto en lugar de tres o cuatro.
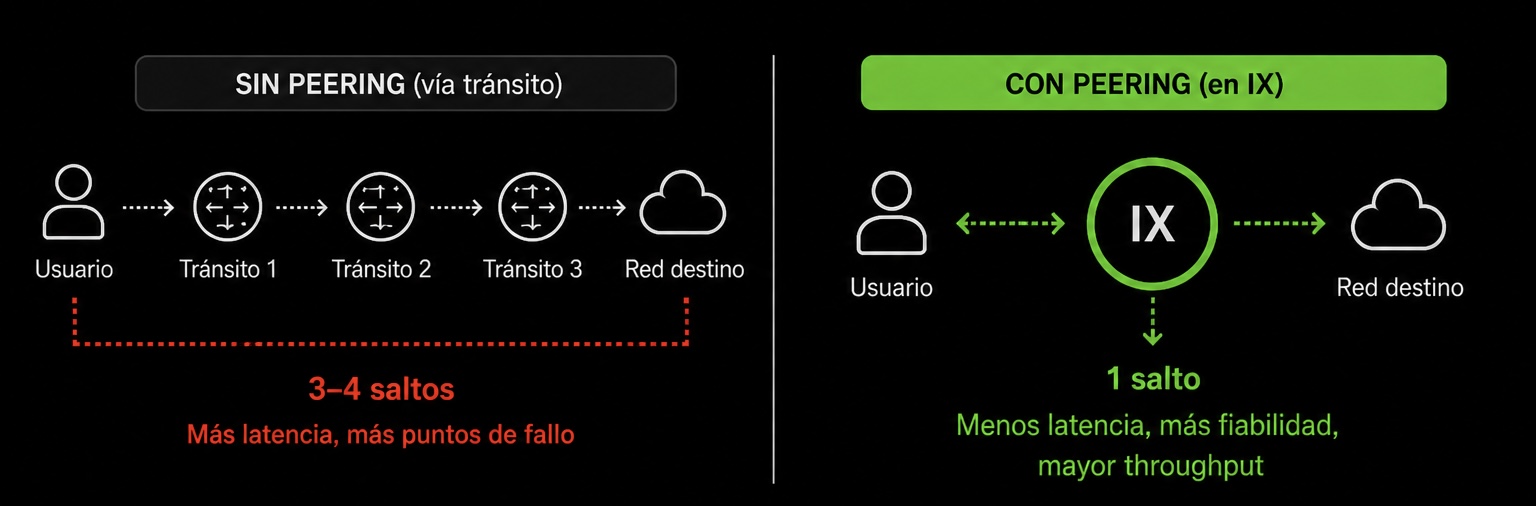
Hacemos peering en cada IX que podemos porque el objetivo es simple: mantener nuestra red lo más interconectada posible y reducir el número de saltos entre CubePath y el resto de internet.
Por qué esto importa para la latencia. Cada salto en un camino de red añade latencia. Un router necesita recibir el paquete, buscar la ruta y reenviarlo. Eso lleva tiempo, normalmente una fracción de milisegundo, pero se acumula a lo largo de múltiples saltos. Al hacer peering directo con grandes redes, CDNs, proveedores cloud e ISPs de usuario final en ubicaciones IX, eliminamos esos saltos intermedios de la ecuación. El resultado es una latencia mediblemente menor para tus usuarios.
Por qué esto importa para la fiabilidad. Menos saltos significa menos cosas que pueden fallar. Cada router en el camino es un punto potencial de fallo o congestión. El peering directo en un IX elimina esos puntos intermedios por completo. Si tenemos peering con el ISP de un usuario en el mismo exchange, el tráfico se queda local en esa instalación. Sin tránsito de larga distancia, sin decisiones de enrutamiento de terceros, sin sorpresas.
Por qué esto importa para el throughput. El peering en IX normalmente ofrece mayor capacidad y menor coste que el tránsito. Cuando una parte significativa de tu tráfico va a redes con las que hacemos peering directo, no estás compitiendo por ancho de banda en los enlaces congestionados de un proveedor de tránsito. El tráfico fluye por conexiones de peering dedicadas con capacidad que controlamos y monitorizamos.
Cuantas más redes tengamos en peering, más tráfico toma caminos directos. Y cuantos más caminos directos toma el tráfico, más rápidos y fiables son tus servicios para los usuarios finales.
Anycast: Una IP, Servida desde el PoP Más Cercano
Anycast es una técnica de enrutamiento donde la misma dirección IP se anuncia desde múltiples ubicaciones simultáneamente. Cuando un usuario envía una petición a una IP Anycast, el enrutamiento BGP lo dirige de forma natural al PoP más cercano que anuncia esa dirección. El usuario no elige. La red lo hace automáticamente basándose en la proximidad de enrutamiento.
CubePath usa Anycast en toda nuestra red de PoPs. Esto es lo que permite:
Direccionamiento geográfico del tráfico sin trucos de DNS. El enfoque tradicional para dirigir usuarios al servidor más cercano depende de GeoDNS, que resuelve el mismo hostname a diferentes IPs según la ubicación del usuario. Funciona, pero es lento de actualizar, impreciso y depende de que se respeten los TTLs de DNS. Anycast se salta todo eso. Una IP, anunciada desde cada PoP, y la red se encarga del resto.
Failover instantáneo entre ubicaciones. Si un PoP se cae, BGP retira la ruta Anycast de esa ubicación. El tráfico se redirige automáticamente al siguiente PoP más cercano en segundos. Sin esperar propagación DNS, sin esperar TTLs, sin intervención manual. La IP sigue siendo la misma, el usuario es re-enrutado de forma transparente.
Latencia reducida en la primera conexión. Los handshakes TLS son sensibles a la latencia. Requieren múltiples ida y vuelta entre cliente y servidor antes de que fluyan datos. Cuando la IP Anycast resuelve al PoP más cercano, esas ida y vuelta son más cortas y la conexión se establece más rápido. Para servicios HTTPS, esto se traduce directamente en un time-to-first-byte más rápido.
Resiliencia natural contra DDoS. Anycast distribuye el tráfico entrante entre todos los PoPs que anuncian la dirección. Durante un ataque DDoS volumétrico, el tráfico se reparte entre múltiples ubicaciones en vez de golpear un solo punto. Cada PoP absorbe una fracción del ataque, haciendo mucho más difícil saturar cualquier ubicación individual.
Cómo Usamos Anycast en CubePath
Un buen ejemplo es nuestra infraestructura DNS. Los resolvers DNS de CubePath se anuncian vía Anycast desde todos nuestros PoPs. Cuando tu servidor hace una consulta DNS, llega al resolver más cercano automáticamente. Un servidor en España consulta al PoP local. Un servidor en Miami consulta al suyo. Misma IP, diferente ubicación física, menor latencia posible. Si un PoP se cae, las consultas DNS se enrutan al siguiente más cercano sin ningún cambio de configuración.
También usamos Anycast como la base de nuestros servicios de CDN y mitigación DDoS. El tráfico de los usuarios finales llega primero al PoP más cercano, donde puede ser filtrado, cacheado o reenviado al servidor origen a través de nuestro backbone privado. Esta arquitectura hace que tanto la capa de seguridad como la de entrega de contenido se beneficien de la distribución geográfica sin que los clientes tengan que configurar nada.
Cómo Encaja Todo
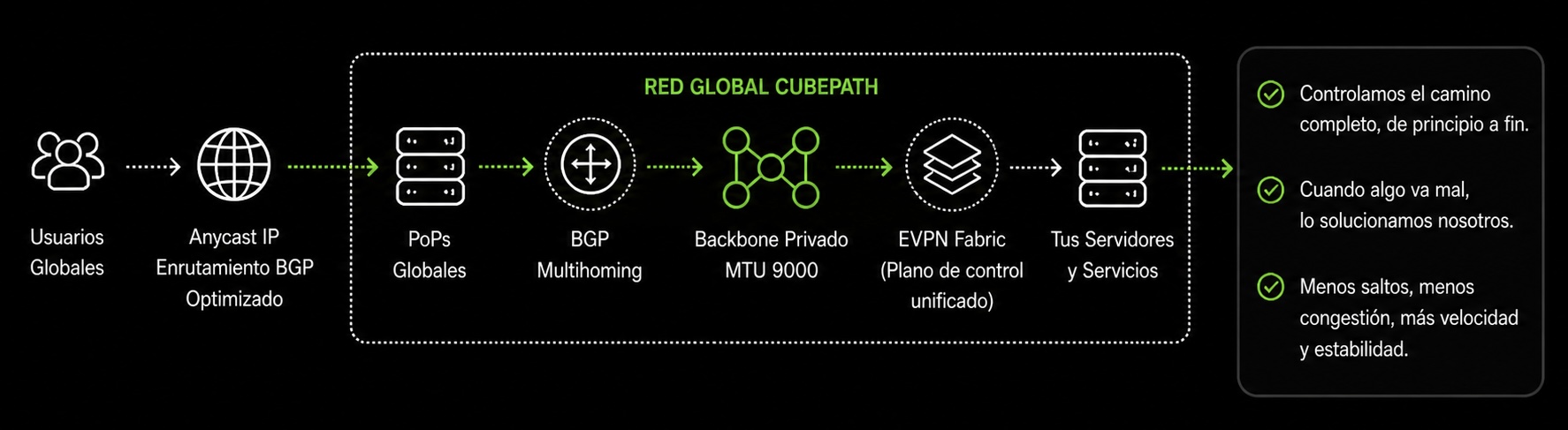
Nuestra red global no es una colección de funcionalidades aisladas. Los PoPs, BGP multihoming, Anycast y el backbone privado con MTU 9000 trabajan juntos como una sola infraestructura.
El tráfico entra por el PoP más cercano gracias a Anycast y las rutas BGP optimizadas. Viaja a través de nuestro backbone privado para llegar a los servidores que ejecutan tus cargas de trabajo, con MTU 9000 asegurando que la transferencia interna de datos sea lo más eficiente posible. Si cualquier componente falla, ya sea un proveedor de tránsito, un PoP o un servidor, la red se re-enruta automáticamente a nivel BGP.
Esto es lo que diferencia a CubePath de proveedores que alquilan capacidad de red de otro. Nosotros controlamos el camino completo, desde el primer paquete del usuario hasta el servidor que procesa la petición. Cuando algo va mal, no abrimos un ticket con un upstream. Lo arreglamos nosotros.
Para equipos ejecutando APIs sensibles a latencia, aplicaciones distribuidas globalmente, servicios en tiempo real, o cualquier cosa donde el rendimiento de red impacta directamente en la experiencia de usuario, este es el tipo de red que quieres debajo de tu infraestructura.
Internamente, nuestro fabric de red corre sobre EVPN (Ethernet VPN), la misma tecnología que usan los proveedores cloud a hiperescala. EVPN usa BGP para aprender dónde vive cada servidor y cada dirección en la red, así que el tráfico se reenvía de forma inteligente en vez de inundarse a todas partes como en los setups tradicionales. Es lo que nos permite extender redes privadas entre PoPs de forma transparente, manejar la conectividad multi-sitio de forma nativa, y escalar el fabric a medida que añadimos más servidores y ubicaciones sin que la red se degrade. El mismo BGP que gestiona nuestro enrutamiento de internet, nuestro peering y nuestro Anycast también gobierna nuestro fabric interno. Un plano de control unificado para toda la red.
Esto es lo que diferencia a CubePath de proveedores que alquilan capacidad de red de otro. Nosotros controlamos el camino completo, desde el primer paquete del usuario hasta el servidor que procesa la petición. Cuando algo va mal, no abrimos un ticket con un upstream. Lo arreglamos nosotros.
Hacia Dónde Vamos
Seguimos expandiendo nuestra huella de PoPs y añadiendo conexiones de peering en cada ubicación. Más PoPs significa caminos más cortos a más usuarios. Más peering significa menos dependencia del tránsito y mejor enrutamiento hacia las grandes redes e ISPs de usuario final.
A medida que hacemos crecer CubePath Managed Kubernetes, los clusters GPU y el resto de nuestra plataforma, la red sigue siendo la base. Rápida, redundante, distribuida globalmente y totalmente bajo nuestro control.
Construimos esta red porque creemos que los proveedores de infraestructura deberían ser dueños de su red, no alquilarla. Todo lo que ofrecemos en CubePath se apoya en esta base, y creemos que se nota la diferencia.